Silver bullet
Tensorflow Classification (version 1 code) Mnist / Dropout 적용 / Batch-Normalization & He initialization 적용 본문
AI/AI
Tensorflow Classification (version 1 code) Mnist / Dropout 적용 / Batch-Normalization & He initialization 적용
밀크쌀과자 2024. 7. 13. 00:13tf.placeholder()
- 실제 Data가 담길 일종의 접시
- 용도에 따라 Data type과 Shape를 설정하여 선언하고 사용
- 계산 그래프를 실행(sess.run)할때 사용자가 실제 데이터(Train/Test/Unseen, etc.)를 흘려보낼 수 있는 통로
feed_dict
- sess.run() 함수에게 전달하는 Placeholder와 실제 Data의 쌍(Dictionary)
- Key에 해당하는 Placeholder는 고정, 실행단계 에서 흘려보낼 Data만 Value에 입력
* 이미지 데이터는 feature scaling이 딱히 필요없다. 모든 x데이터 열이 0~255값을 가지기 때문. 때로 255를 나눠주는 것 까지 하는 경우는 있다.
from tensorflow.keras import datasets # MNIST Data는 Tensorflow 2.x를 통해 가져올 수 있습니다.
(train_data, train_label), (test_data, test_label) = datasets.mnist.load_data()
print(train_data.shape) # # of training data == 60000, each data = 28px * 28px
print(test_data.shape) # # of test data == 10000
print(train_label.shape)
print(test_label.shape)import matplotlib.pyplot as plt
plt.imshow(train_data[0], cmap='gray') # 60000장의 train data 중 첫번째 data
Normalization
# 각 이미지(28px * 28px)는 0~255 사이의 숫자로 이루어져 있습니다.
print(train_data.min())
print(train_data.max())
# 각 이미지를 [28행 x 28열]에서 [1행 x 784열]로 펼쳐줍니다.
# 각 이미지 내의 pixel 값을 [0~255]에서 [0~1]로 바꿔줍니다.
train_data = train_data.reshape(60000, 784) / 255.0 # reshape(60000, -1)
test_data = test_data.reshape(10000, 784) / 255.0
train_data.shape(60000, 784)One-hot encoding
# 각 label을 integer value에서 one-hot vector로 변경해줍니다. (Tensorflow 2.x 활용)
from tensorflow.keras import utils
train_label = utils.to_categorical(train_label) # 0~9 -> one-hot vector
test_label = utils.to_categorical(test_label) # 0~9 -> one-hot vector# 기존의 integer label들이 아래와 같은 one-hot vector들로 변경된 것을 확인할 수 있습니다.
import pandas as pd
pd.DataFrame(train_label).head(3)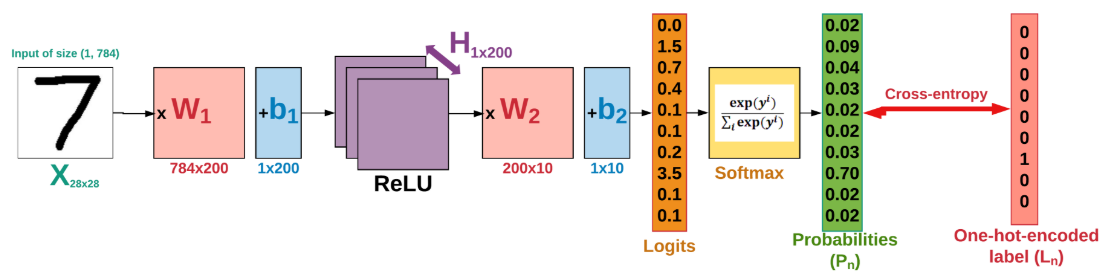
2. Build the model
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # https://stackoverflow.com/questions/35911252/disable-tensorflow-debugging-information
tf.logging.set_verbosity(tf.logging.ERROR)# 데이터가 흘러들어올 접시(placeholder) 만들기
X = tf.placeholder(tf.float32, [None, 784]) # [# of batch data, # of features(columns) == 총 784개의 열]
Y = tf.placeholder(tf.float32, [None, 10]) # 0~9 == 총 10개의 열
# 모든 Parameter Theta는 Variable로 선언
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01)) # stddev 표준편차
L1 = tf.nn.relu(tf.matmul(X, W1))
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3) # 마지막 층도 행렬곱까지만 진행3. Set the criterion
# cost = tf.losses.mean_squared_error(Y, model) # for Regression
cost = tf.losses.softmax_cross_entropy(Y, model) # for Classification, "cross-entropy" after "softmax"
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost) # Select optimizer & connect with cost function (recommended start : "Adam")4. Train the model
init = tf.global_variables_initializer() # Initialize all global variables (Parameter Theta)
sess = tf.Session()
sess.run(init)
# Gradient descent를 적용하기 전까지 한번에 밀어넣는 데이터의 수 지정 (Batch size == 하나의 데이터 덩어리 내 데이터 수)
batch_size = 100 # [100, 784]
total_batch = int(len(train_data) / batch_size)
print(total_batch)# import tqdm
# for epoch in tqdm.notebook.tqdm(range(15)):
for epoch in range(15):
total_cost = 0 # 매 epoch 마다의 평균 에러 값 계산을 위해 활용됩니다.
batch_idx = 0 # 매 batch 마다 꺼낼 데이터의 시작 index 값 지정을 위해 활용됩니다.
for i in range(total_batch): # iterate over # of batches
# Training data(60000장)에서 batch_size(100개) 만큼 순서대로 꺼내어 학습에 활용해줍니다.
batch_x = train_data[ batch_idx : batch_idx + batch_size ]
batch_y = train_label[ batch_idx : batch_idx + batch_size ]
sess.run(optimizer, feed_dict={X: batch_x, Y: batch_y}) # 먹여줄(feed) 딕셔너리(dict)
# 이번 batch를 기준으로 계산이 끝난 Cross-entropy 값을 total_cost에 더해줍니다. (epoch 종료 후 평균을 냅니다.)
batch_cost = sess.run(cost, feed_dict={X: batch_x, Y: batch_y})
total_cost = total_cost + batch_cost
# 다음 for loop에서 꺼낼 데이터의 시작 index 번호를 batch_size(100) 만큼 증가시킵니다.
batch_idx += batch_size
# (이번 epoch가 종료되었을 시점의) training data 기준 Cross-entropy 값을 계산합니다.
training_cost = total_cost / total_batch
# sess.run(cost, feed_dict={X: batch_x, Y: batch_y})
# (이번 epoch가 종료되었을 시점의) test data 기준 Cross-entropy 값을 계산합니다.
test_cost = sess.run(cost, feed_dict={X: test_data, Y: test_label})
print('Epoch: {}'.format(epoch + 1),
'|| Avg. Training cost = {:.3f}'.format(training_cost),
'|| Current Test cost = {:.3f}'.format(test_cost))
print('Learning process is completed!')Epoch: 1 || Avg. Training cost = 0.387 || Current Test cost = 0.193
Epoch: 2 || Avg. Training cost = 0.141 || Current Test cost = 0.123
Epoch: 3 || Avg. Training cost = 0.087 || Current Test cost = 0.108
Epoch: 4 || Avg. Training cost = 0.058 || Current Test cost = 0.116
Epoch: 5 || Avg. Training cost = 0.039 || Current Test cost = 0.111
Epoch: 6 || Avg. Training cost = 0.027 || Current Test cost = 0.093
Epoch: 7 || Avg. Training cost = 0.019 || Current Test cost = 0.101
Epoch: 8 || Avg. Training cost = 0.015 || Current Test cost = 0.098
Epoch: 9 || Avg. Training cost = 0.013 || Current Test cost = 0.097
Epoch: 10 || Avg. Training cost = 0.011 || Current Test cost = 0.105
Epoch: 11 || Avg. Training cost = 0.008 || Current Test cost = 0.099
Epoch: 12 || Avg. Training cost = 0.006 || Current Test cost = 0.094
Epoch: 13 || Avg. Training cost = 0.005 || Current Test cost = 0.110
Epoch: 14 || Avg. Training cost = 0.004 || Current Test cost = 0.124
Epoch: 15 || Avg. Training cost = 0.004 || Current Test cost = 0.129
Learning process is completed!5. Test the model
# Test data에서 첫번째 행(1행 x 784열)을 꺼내는 코드입니다.
# (Scikit-learn의 첫번째 실습이었던 Linear-regression 실습에서 하나의 열을 꺼낼 때 행렬 형태로 꺼내던 방법을 떠올려보세요.)
# 2차원 행렬로 꺼내야 함.
test_data[0:1, :].shape
# 데이터 1건에 대하여 마지막 output layer의 출력값을 얻을 수 있습니다. (softmax 적용 전의 10개 숫자)
sess.run(model, feed_dict={X: test_data[0:1, :]})
# 위 10개의 숫자 중 가장 큰 값의 index 번호를 얻어냅니다 (np.argmax와 동일)
sess.run(tf.argmax(model, 1), feed_dict={X: test_data[0:1, :]}) # argmax 함수의 두번째 argument "1"은 행 방향을 의미합니다.
# 실제 정답인 test label 중 첫번째 행의 가장 큰 값의 index 번호를 얻어내어 비교함으로써 모델이 맞췄는지 확인이 가능합니다.
sess.run(tf.argmax(Y, 1), feed_dict={Y: test_label[0:1, :]})정확도 계산 (tf.argmax / tf.equal / tf.cast / tf.reduce_mean 활용)
# tf.argmax([0.1 0 0 0.7 0 0.2 0 0 0 0]) -> 3 (가장 큰 값의 index를 return)
# tf.argmax(model, 1) -> [1, 1, 0, 0]
# tf.argmax(Y, 1) -> [1, 0, 1, 0]
# tf.equal(~~~, ~~~) -> [True, False, False, True]
# tf.cast(~~~~) -> [1.0, 0.0, 0.0, 1.0]
# tf.reduce_mean(~~~) -> 0.5
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1)) # model : 예측값, Y : 실제 정답
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32)) # 자료형 변환(type-"cast") 후, 차원을 줄이면서(reduce) 평균(mean) 계산
# 10,000건의 Test data 전체에 대해 모델의 정확도를 계산합니다.
print('정확도 :', sess.run(accuracy,
feed_dict={X: test_data,
Y: test_label}))정확도 : 0.9766# 모델 예측 결과값
predicted_labels = sess.run(tf.argmax(model, 1), feed_dict={X: test_data})
print(list(predicted_labels)[:10])
# 실제 정답
import numpy as np
print(np.argmax(test_label, axis=1)[:10])Dropout
import numpy as np
import matplotlib.pyplot as plt
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # https://stackoverflow.com/questions/35911252/disable-tensorflow-debugging-information
tf.logging.set_verbosity(tf.logging.ERROR)1. Prepare the data
from tensorflow.keras import datasets, utils
(train_data, train_label), (test_data, test_label) = datasets.mnist.load_data()
train_data = train_data.reshape(60000, 784) / 255.0
test_data = test_data.reshape(10000, 784) / 255.0
train_label = utils.to_categorical(train_label) # 0~9 -> one-hot vector
test_label = utils.to_categorical(test_label) # 0~9 -> one-hot vector2. Build the model
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
# Dropout을 적용하며 layer마다 살려줄 node의 비율을 지정합니다.
# 이 때에도 placeholder를 사용해야 합니다.
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
L1 = tf.nn.dropout(L1, keep_prob) # (Dropout을 적용할 layer, 살릴 비율)
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
L2 = tf.nn.dropout(L2, keep_prob) # Dropout을 적용할 layer & 살릴 비율
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)3. Set the criterion
cost = tf.losses.softmax_cross_entropy(Y, model)
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)4. Train the model
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(len(train_data) / batch_size)
print(total_batch)
for epoch in range(15):
total_cost = 0
batch_idx = 0
for i in range(total_batch):
batch_x = train_data[ batch_idx : batch_idx + batch_size ]
batch_y = train_label[ batch_idx : batch_idx + batch_size ]
sess.run(optimizer, feed_dict={X: batch_x,
Y: batch_y,
keep_prob: 0.8}) # 살릴 비율 지정, node 중 80%만 유지하고 20%를 train 시마다 off
batch_cost = sess.run(cost, feed_dict={X: batch_x,
Y: batch_y,
keep_prob: 0.8}) # 살릴 비율 지정, node 중 80%만 유지하고 20%를 train 시마다 off
total_cost = total_cost + batch_cost
batch_idx += batch_size
training_cost = total_cost / total_batch
print('Epoch: {}'.format(epoch + 1),
'|| Avg. Training cost = {:.3f}'.format(training_cost))
print('Learning process is completed!')Epoch: 1 || Avg. Training cost = 0.415
Epoch: 2 || Avg. Training cost = 0.157
Epoch: 3 || Avg. Training cost = 0.106
Epoch: 4 || Avg. Training cost = 0.080
Epoch: 5 || Avg. Training cost = 0.066
Epoch: 6 || Avg. Training cost = 0.052
Epoch: 7 || Avg. Training cost = 0.045
Epoch: 8 || Avg. Training cost = 0.040
Epoch: 9 || Avg. Training cost = 0.034
Epoch: 10 || Avg. Training cost = 0.032
Epoch: 11 || Avg. Training cost = 0.029
Epoch: 12 || Avg. Training cost = 0.027
Epoch: 13 || Avg. Training cost = 0.025
Epoch: 14 || Avg. Training cost = 0.023
Epoch: 15 || Avg. Training cost = 0.021
Learning process is completed!5. Test the model
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('정확도:', sess.run(accuracy,
feed_dict={X: test_data,
Y: test_label,
keep_prob: 1})) # 살릴 비율 지정, 정확도를 측정하는 Test 단계에서는 전체 Node를 살려줘야 합니다.* test data를 예측할때는 dropout을 켜면 안된다. 정확도를 측정하는 Test 단계에서는 전체 Node를 살려줘야 합니다.
정확도: 0.9804
+ Appendix. Save the predicted values
sess.run(tf.argmax(model, 1),feed_dict={X: test_data[:5, :] ,keep_prob: 1})
# 모델의 예측값을 labels에 저장
labels = sess.run(tf.argmax(model, 1),
feed_dict={X: test_data,
Y: test_label,
keep_prob: 1})
print(labels)
fig = plt.figure(figsize=(10, 10))
for i in range(10):
subplot = fig.add_subplot(2, 5, i + 1)
subplot.set_xticks([])
subplot.set_yticks([])
subplot.set_title(labels[i])
subplot.imshow(test_data[i].reshape((28, 28)),
cmap=plt.cm.gray_r)
plt.show() # 상단의 번호가 예측된 숫자, 아래의 이미지가 실제 데이터(이미지 내 숫자)
딥러닝 기초 10강. Tensorflow v1 : Classification (5) -Batch-Normaliation & He initialization 적용
내용 추가 예정
'AI > AI' 카테고리의 다른 글
'AI/AI' Related Articles
more



