Silver bullet
Weight Initialization & Weight regularization / Mini-Batch GD & Adam optimizer 본문
Weight Initialization & Weight regularization / Mini-Batch GD & Adam optimizer
밀크쌀과자 2024. 7. 12. 16:101. Weight Initialization
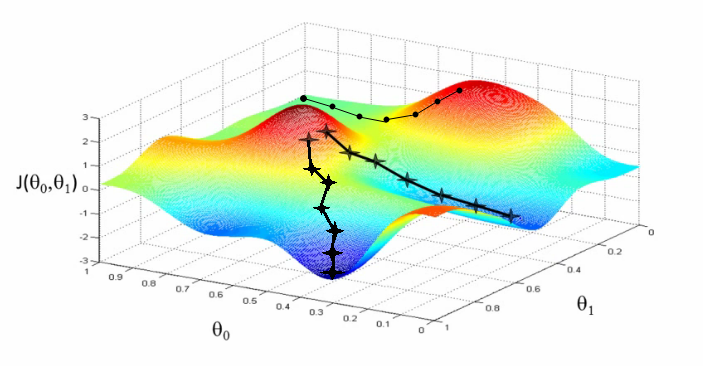
- Gradient descent를 적용하기 위한 첫 단계는 모든 Parameter θ를 초기화 하는 것
- 초기화 시점의 작은 차이가 학습의 결과를 뒤바꿀 수 있으므로 보다 나은 초기화 방식을 모색하게 됨
- Perceptron의 Linear combination 결과 값 (Activation function으로의 입력값)이 너무 커지거나 작아지지 않게 만들어주려는 것이 핵심
- 발전된 초기화 방법들을 활용해 Vanishing gradient 혹의 Exploding gradient 문제를 줄일 수 있음
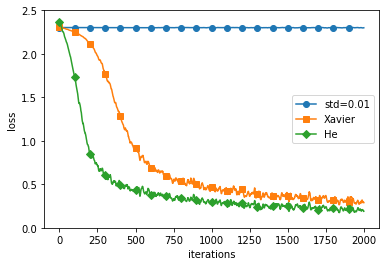
1) Xavier Initialization
- 활성화 함수로 Sigmoid 함수나 tanh함수를 사용할 때 적용
- 다수의 딥러닝 라이브러리들에 Dafault로 적용되어 있음
- 표준편차가 sqrt(1/n)인 정규 분포를 따르도록 가중치 초기화
2) He Initialization
- 활성화 함수가 ReLU일 때 적용
- 표준편차가 sqrt(2/n)인 정규 분포를 따르도록 가중치 초기화
2. Weight regularization
- 기존의 Gradient Descent 계산 시 y축에 위치해 있던 Cost function은 Training data에 대해 모델이 발생시키는 Error 값의 지표
- Training data만 고려된 이러한 Cost Function을 기준으로 하여 Gradient Descent를 적용하면 Overfitting에 빠질 수 있음
- 모델이 복잡해질수록 모델 속에 숨어있는 θ 들은 그 개수가 많아지고 절대값이 커지는 경향이 있음 (숨겨져 있던 θ 들의 값을 갖게 됨)
- 모델이 복잡해질수록 그 값이 커지는 θ에 대한 함수를 기존의 Cost function에 더하여 Trade-off 관계속에서 최적값을 찾을 수 있음
1) L1 regularization (Lasso)
- 가중치의 절대값의 합에 비례하여 가중치에 패널티를 준다.
- 관련성이 없거나 매우 낮은 특성의 가중치를 정확히 0으로 유도하여, 모델에서 해당 특성을 배제하는 데 도움이 됨. (== Feature selection 효과)
2) L2 regularization (Ridge)
- 가중치의 제곱의 합에 비례하여 가중치에 패널티를 준다.
- 큰 값을 가진 가중치를 더욱 제약하는 효과가 있음
L1 & L2 Regularization = Weight Decay (가중치 감퇴/감소)
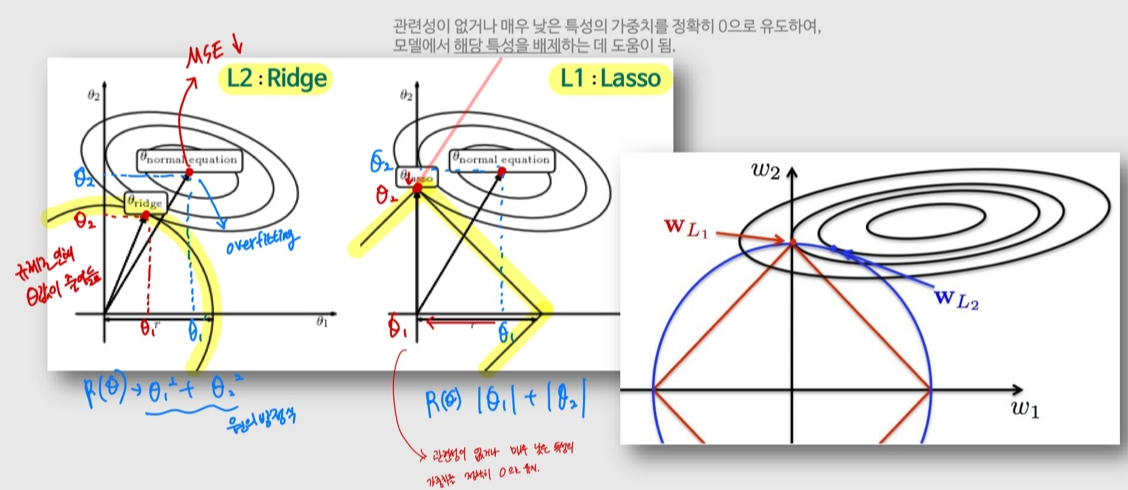
Lasso와 Ridge를 둘 다 적용한 것은 Elastic Net
Regularization Rate (정규화율 / Lambda)
- 스칼라 값 (Hyper-parameter)
- 정규화 함수의 상대적 중요도를 지정
- 정규화율을 높이면 과적합이 감소하지만 모델의 정확성이 떨어질 수 있음(Underfitting)
- θ의 수가 아주 많은 신경망은 정규화율을 아주 작게 주기도 함
Advanced gradient descent algorithm
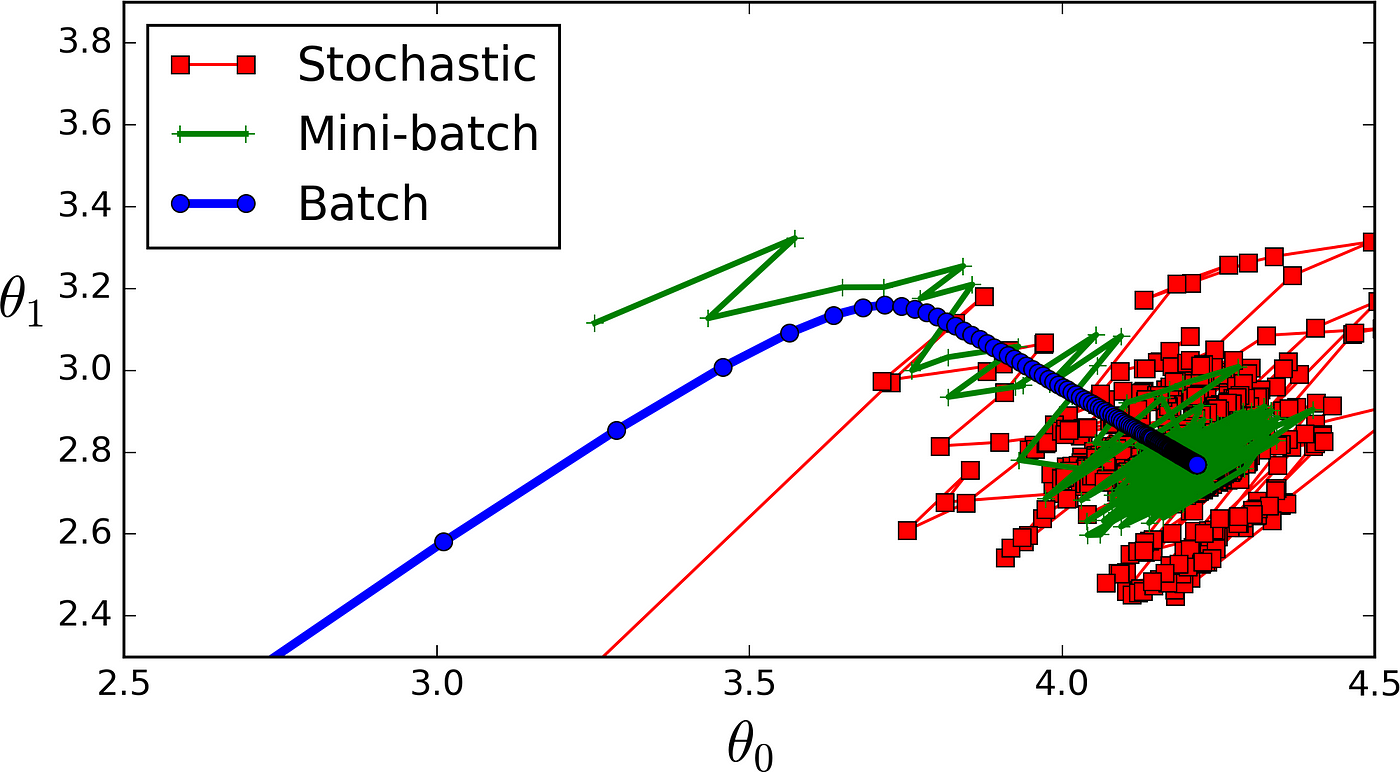
(Full-Batch) Gradient Descent
모든 Training data에 대해 Cost를 구하고 Cost function값을 구한 다음 이를 기반으로 Gradient descent를 적용
- Training data가 많으면 Cost function 등의 계산에 필요한 연산의 양이 많아진다. (학습이 오래걸림)
- Weight initialization 의 결과에 따라 Global minimum이 아닌 local minima으로 수렴할 수 있다.
Stochastic Gradient Descent (SGD, 확률적 경사하강법)
하나의 Training data (Batch Size = 1)마다 Cost를 계산하고 바로 Gradient descent를 적용하여 weight를 빠르게 update
- 한 개의 Training data마다 매번 weight를 갱신하기 때문에 신경망의 성능이 들쑥날쑥 변함(Cost 값이 안정적으로 줄어들지 않음)
- 최적의 Learning rate를 구하기 위해 일일이 튜닝하고 수렴조건(early-Stop)을 조정해야 함
Mini-Batch Stochastic Gradient Descent
Training data에서 일정한 크기(== Batch size)의 데이터를 선택하여 Cost function 계산 및 Gradient descent 적용
- 앞선 두가지 Gradient descent 기법을 단점을 보완하고 장점을 취함.
- 설계자의 의도에 따라 속도와 안정성을 동시에 관리할 수 있으며, GPU 기반의 효율적인 병렬 연산이 가능해진다.
Batch vs Epoch, and Iteration
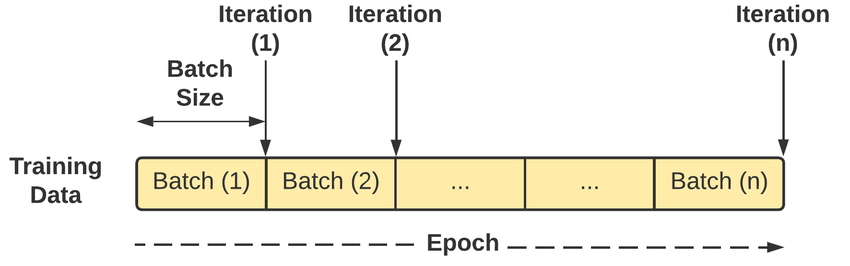
총 데이터 수가 10,000개, batch size가 1,000일 경우,
1 iteration = 1,000개의 데이터에 대한 Gradient descent
1 epoch = 10,000 / batch size = 10 iteration

Adam (Adaptive Moment Estimation) Optimizer
- Momentum과 AdaGrad/RMSProp의 이점을 조합 (Momentum : 기울기 방향으로 물체가 가속되는 관성의 원리 적용, 속도라는 변수 추가)
- Adaptive learning rate가 적용되어 learning rate에 대한 탐색의 필요성이 줄어듦
- 알아서 learning rate를 적당히 조절해줌


