Silver bullet
SVM - Soft-margin Kernelized SVM / StandardScaler, HPO & GridSearchCV 본문
SVM - Soft-margin Kernelized SVM / StandardScaler, HPO & GridSearchCV
밀크쌀과자 2024. 7. 10. 17:34SVM 1) Support Vector Machine (서포트 벡터 머신)
: 패턴 인식을 위한 지도 학습 모델, 분류 뿐만 아니라 회귀에도 활용할 수 있음
→ 딥러닝 이전에 뛰어난 성능으로 많은 주목을 받았던 머신러닝 알고리즘
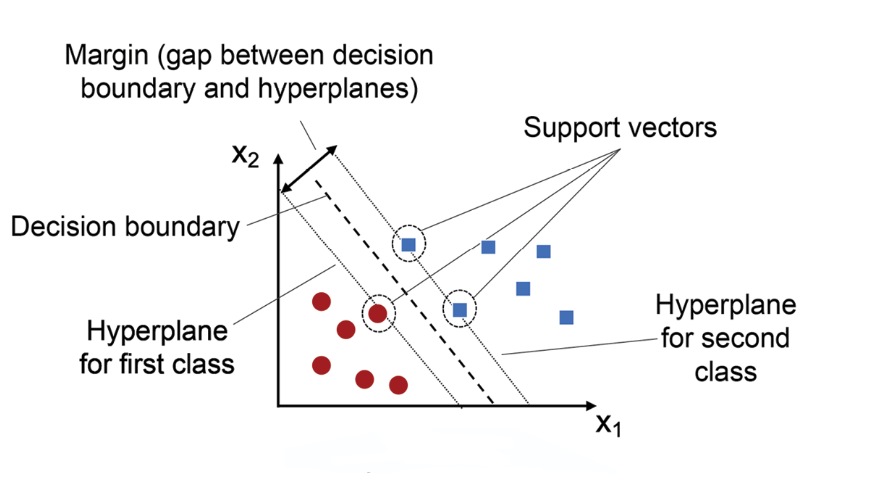
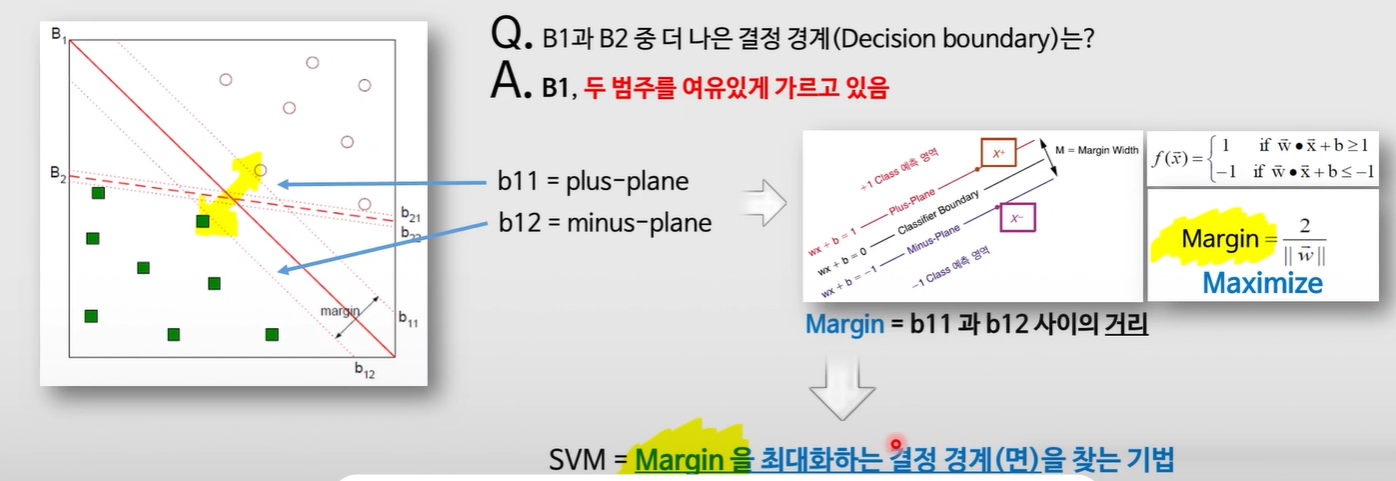
SVM = Margin을 최대화하는 결정 경계(면)을 찾는 기법
그러나 현실에서는 매우 엄격하게 2개의 클래스로만 데이터를 분리하기 어려움
→ 소수의 noise로 인해 결정 경계(면) 을 찾지 못할 수도 있음
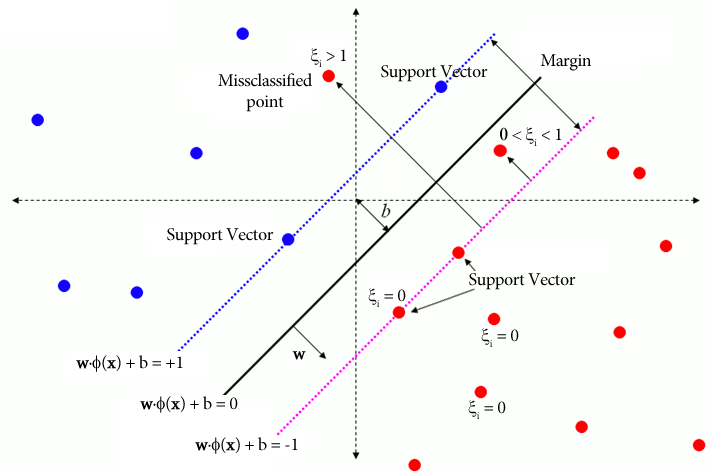
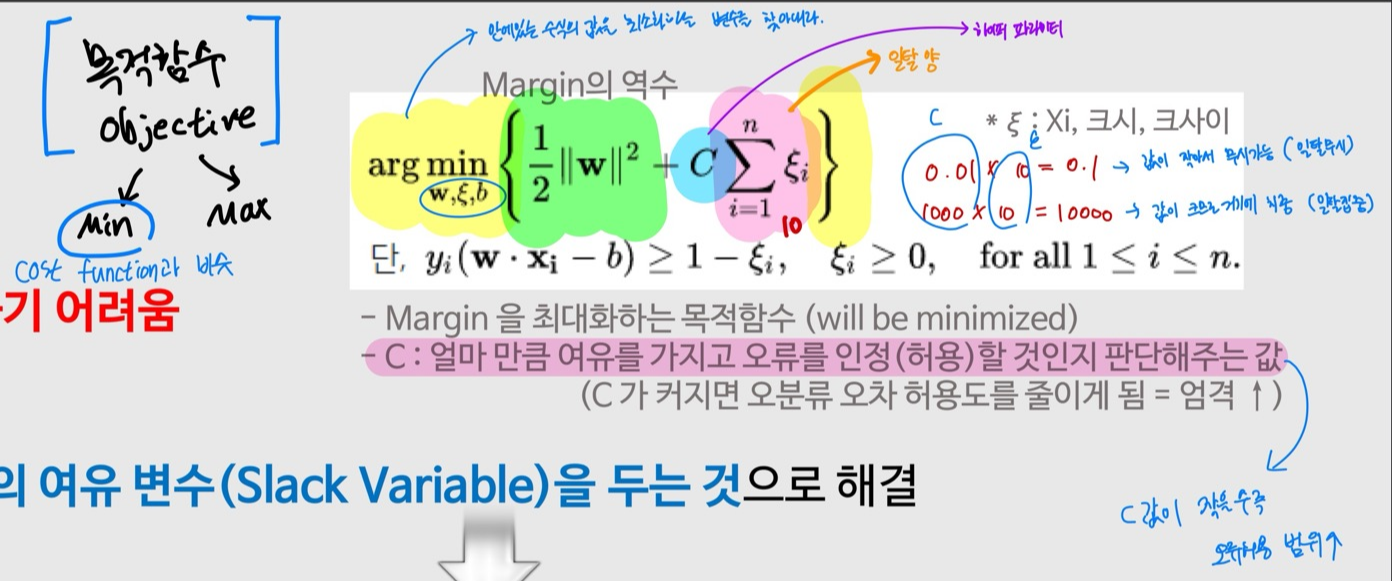
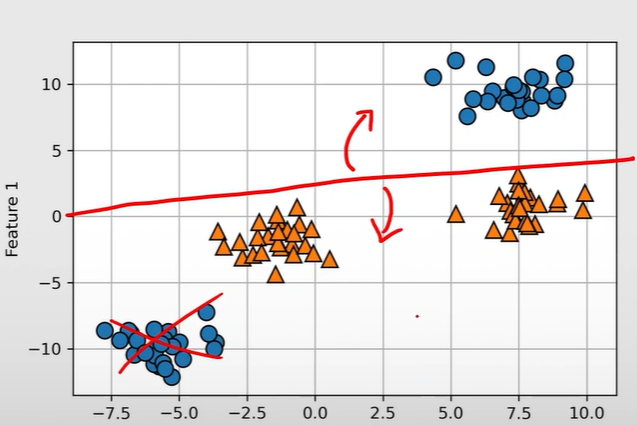
→ 서포트 벡터가 위치한 Plus & Minus plane에 약간의 여유 변수(Slack Variable)을 두는 것으로 해결
SVM 2) Soft-Margin SVM

SVM 3) Kernel Support Vector Machine
데이터가 선형적으로 분리되지 않을 경우는? (Linearly-Unseparable, 선형 분리 불가)
→ Original data가 놓여져있는 차원을 비선형 매핑(Mapping)을 통해 고차원 공간으로 변환하는 것으로 해결
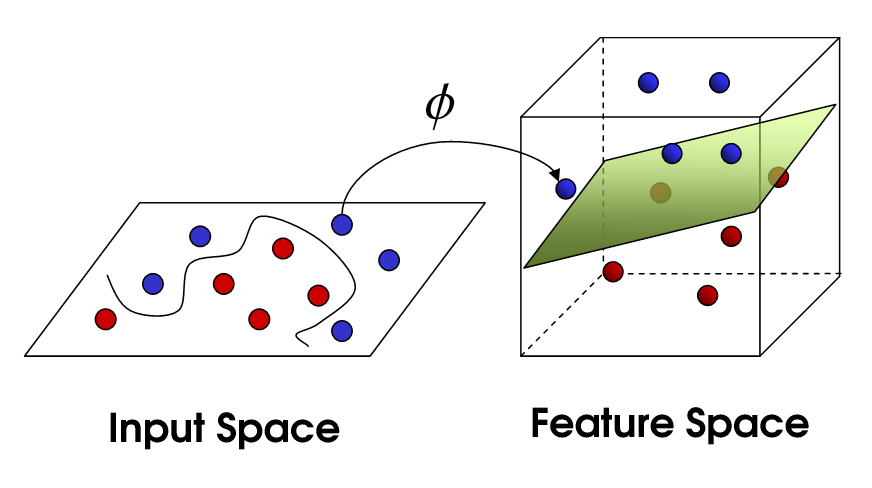
Kernel Function(Hyper-parameter) : The selection of kernel function is testing & research issue
Kernelized Support Vector Machine (Scikit-learn, with Custom_mglearn) 실습
(실제 실습) RBF 커널 SVM을 유방암 데이터셋에 적용해보기
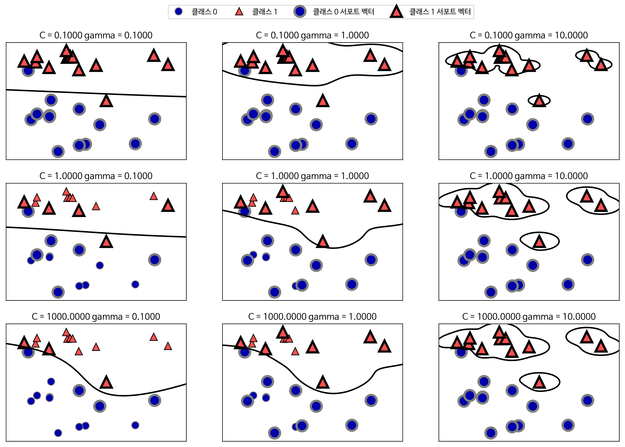
C : 얼마만큼 여유를 가지고 오류를 인정(허용)할 것인지 판단해주는 값 → c값이 작을 수록 오류 허용 범위↑, c가 커지면 오차 허용도를 줄이게 됨 = 엄격↑
gemma : 가우시안 커널 단면의 반지름의 역수 → gamma가 커질수록 반지름은 작아지고, gamma가 작아질수록 반지름은 커진다.
rdf (radial basis function) : 가우시안 커널

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0) # stratify=cancer.target : 각 class 비율을 train & test split 시 유지
# gamma를 default 값인'scale'로 적용하면 자동으로 문제가 해결되나(auto-scaling) 직접 문제를 발견하고 해결하기 위해 'auto'로 적용합니다.
svc = SVC(gamma='auto')
svc.fit(X_train, y_train)
print("Accuracy on Training set: {:.3f}".format(svc.score(X_train, y_train)))
print("Accuracy on Test set: {:.3f}".format(svc.score(X_test, y_test)))Accuracy on Training set: 1.000
Accuracy on Test set: 0.629→ Overfitting 발생
이유 : x 데이터의 스케일이 너무 많이 차이난다.
# 각 열의 데이터 분포 확인
plt.figure(figsize=(10,7))
plt.boxplot(X_train)
plt.yscale("symlog")
plt.xlabel("Feature list")
plt.ylabel("Feature size")
plt.show()
# 데이터의 각 열 마다의 Scale이 매우 다름
# Kernelized SVM 에서는 영향이 아주 크다SVM을 위한 데이터 전처리
- 열 마다의 데이터 범위가 비슷해지도록 조정 (Feature Scaling)
- 보통 열마다의 값을 0과 1 사이로 맞추는 방법을 기본적으로 사용 (Min-Max Scaling)
- mean이 0이고, std가 1이 되게 하여 -1 ~ 1 사이의 값으로 맞추는 방법 (StandardScaler)
- 보통 Min-Max Scaling 보다 StandardScaler가 성능이 좋다
* 중요 : Feature Normalization을 할 때는 train 데이터로만 fit을 한다. 절대로 test 데이터는 fit하면 안된다. test 데이터는 transform만 한다. 새로운 데이터가 들어오더라도 transform을 하고 predict를 진행해야 한다.
StandardScaler
# 혹은 데이터의 범위를 0~1 사이로 맞추는 Min-max Normalization(정규화) 대신,
# 평균이 0 & 표준편차가 1 이 되게끔 Standardization(표준화)를 적용할 수도 있습니다.
# 이 때는 sklearn.preprocessing.StandardScaler 를 간편하게 활용할 수 있습니다.
from sklearn.preprocessing import StandardScaler # (sklearn.preprocessing.MinMaxScaler is also available)
sc = StandardScaler()
sc.fit(X_train) # X_train 의 평균과 표준편차를 구함
# As with all the transformations, it is important to fit the scalers to the training data only, not to the full dataset (including the test set).
X_train_scaled = sc.transform(X_train)
X_test_scaled = sc.transform(X_test)
df = pd.DataFrame(X_train_scaled)
df.describe()MinMaxScaler
from sklearn.preprocessing import MinMaxScaler # (sklearn.preprocessing.MinMaxScaler is also available)
sc = MinMaxScaler()
sc.fit(X_train) # X_train 의 평균과 표준편차를 구함
# As with all the transformations, it is important to fit the scalers to the training data only, not to the full dataset (including the test set).
X_train_scaled = sc.transform(X_train)
X_test_scaled = sc.transform(X_test)
df = pd.DataFrame(X_train_scaled)
df.describe()SVC
# from sklearn.svm import SVC
svc = SVC(gamma='auto')
svc.fit(X_train_scaled, y_train)
print("Accuracy on Training set: {:.3f}".format(svc.score(X_train_scaled, y_train)))
print("Accuracy on Test set: {:.3f}".format(svc.score(X_test_scaled, y_test)))Accuracy on Training set: 0.986
Accuracy on Test set: 0.965# C나 gamma 값을 증가시켜 좀 더 복잡한 모델을 만들 수 있음
svc = SVC(C=1000)
svc.fit(X_train_scaled, y_train)
print("Accuracy on Training set: {:.3f}".format(svc.score(X_train_scaled, y_train)))
print("Accuracy on Test set: {:.3f}".format(svc.score(X_test_scaled, y_test)))Accuracy on Training set: 1.000
Accuracy on Test set: 0.958# C나 gamma 값을 증가시켜 좀 더 복잡한 모델을 만들 수 있음
svc = SVC(C=1000, gamma=0.1)
svc.fit(X_train_scaled, y_train)
print("Accuracy on Training set: {:.3f}".format(svc.score(X_train_scaled, y_train)))
print("Accuracy on Test set: {:.3f}".format(svc.score(X_test_scaled, y_test)))Accuracy on Training set: 1.000
Accuracy on Test set: 0.965최적의 Hyper Parameter 를 찾아주는 GridSearch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0) # stratify=cancer.target : 각 class 비율을 train & test split 시 유지
# gamma를 default 값인'scale'로 적용하면 자동으로 문제가 해결되나(auto-scaling) 직접 문제를 발견하고 해결하기 위해 'auto'로 적용합니다.
svc = SVC(gamma='auto')
svc.fit(X_train, y_train)
print("Accuracy on Training set: {:.3f}".format(svc.score(X_train, y_train)))
print("Accuracy on Test set: {:.3f}".format(svc.score(X_test, y_test)))Accuracy on Training set: 1.000
Accuracy on Test set: 0.629from sklearn.preprocessing import StandardScaler # (sklearn.preprocessing.MinMaxScaler is also available)
sc = StandardScaler()
sc.fit(X_train) # X_train 의 평균과 표준편차를 구함
# As with all the transformations, it is important to fit the scalers to the training data only, not to the full dataset (including the test set).
X_train_scaled = sc.transform(X_train)
X_test_scaled = sc.transform(X_test)
df = pd.DataFrame(X_train_scaled)
df.describe()# from sklearn.svm import SVC
svc = SVC(gamma='auto')
svc.fit(X_train_scaled, y_train)
print("Accuracy on Training set: {:.3f}".format(svc.score(X_train_scaled, y_train)))
print("Accuracy on Test set: {:.3f}".format(svc.score(X_test_scaled, y_test)))Accuracy on Training set: 0.986
Accuracy on Test set: 0.965HPO
== Hyper-Parameter Optimization
== Hyper- Parameter Tuning
== Model Tuning
- GridSearch HPO < - 가장 널리 쓰이는 방법, 직관적
- Randomized_Search HPO <- 딥러닝에 도움
- Bayesian-Search HPO <- 베이즈 통계학 vs 빈도주의 통계학
from sklearn.model_selection import GridSearchCV
# 아래 param_grid dict 의 C & gamma 에 후보 Hyper-params 값들을 리스트업합니다.
param_grid = {'C' : [0.1, 1, 10, 100, 1000],
'gamma' : [1, 0.1, 0.01, 0.001, 0.0001],
'kernel' : ['rbf']}
grid = GridSearchCV(SVC(), param_grid, refit=True, verbose=1)
# refit : 찾아진 가장 좋은 params로 estimator를 setting할 지 여부 (setting해줘야 곧바로 predict가 가능)
# verbose : 설명의 자세한 정도 (verbose를 3과 같이 바꿔보시면 더 자세하게 매 param set 마다의 결과를 확인할 수 있습니다.)
grid.fit(X_train_scaled, y_train)
print('The best parameters are ', grid.best_params_)Fitting 5 folds for each of 25 candidates, totalling 125 fits
The best parameters are {'C': 10, 'gamma': 0.01, 'kernel': 'rbf'}from sklearn.metrics import classification_report
grid_predictions = grid.predict(X_test_scaled)
print(classification_report(y_test, grid_predictions)) # Precision, Recall, F1-score 등을 확인할 수 있습니다.
print("Accuracy on Training set: {:.3f}".format(grid.score(X_train_scaled, y_train)))
print("Accuracy on Test set: {:.3f}".format(grid.score(X_test_scaled, y_test))) precision recall f1-score support
0 0.98 0.96 0.97 53
1 0.98 0.99 0.98 90
accuracy 0.98 143
macro avg 0.98 0.98 0.98 143
weighted avg 0.98 0.98 0.98 143
Accuracy on Training set: 0.986
Accuracy on Test set: 0.979

