Silver bullet
비용함수와 경사하강법 (Cost function & MSE) 본문
1. 선형회귀 (Linear Regression)
종속 변수 y와 한 개 이상의 독립 변수 (또는 설명 변수) x 사이의 선형 상관 관계를 모델링하는 회귀분석 기법
: 정답이 있는 데이터의 추세를 잘 설명하는 선형 함수를 찾아 x에 대한 y를 예측
y = ax + b → y = a(가중치) * x + b(보정치 / bias 편향)
- 1개의 독립변수(x)가 1개의 종속변수(y)에 영향을 미칠 때 : 단순 회귀 분석(Simple Regression Analysis)
- 2개 이상의 독립변수(x)가 1개의 종속변수(y)에 영향을 미칠 때 : 다중 회귀 분석(Multivariate Regression Analysis)
- → 가장 적합한 θ (Theta) 들의 Set을 찾는 것이 목표
- x 데이터가 많으면 → 선형결합 (Linear combination)
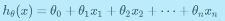
2. Cost Function (비용함수)
= Loss, Error, Objective(MIN & MAX)
: 예측 값과 실제 값의 차이를 기반으로 모델의 성능(정확도)을 판단하기 위한 함수
Linear regression의 경우, Mean squared error function(평균 제곱 오차 함수)을 활용
→ MSE(Cost)가 최소가 되도록 하는 θ (parameter, a & b)를 찾아야 한다.(y = ax + b)

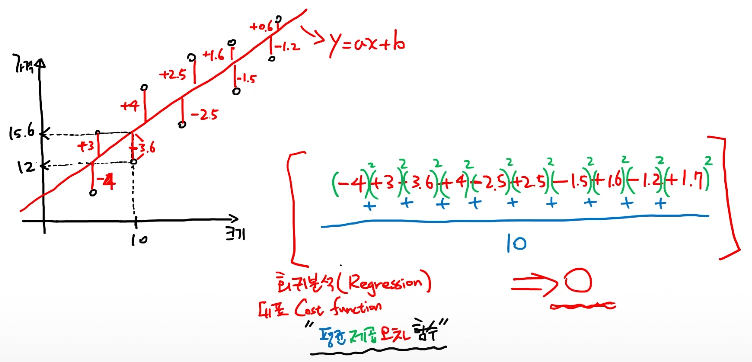
- MSE (제곱)
- MAE (절대값)
- MAPE (비율)
- RMSE (루트)
J(θ) : 비용함수
Objective(MIN) = Cost function
Objective(MAX) != Cost function
3. Gradient Descent Algorithm (경사하강법)
- Cost function 의 값을 최소로 만드는 θ 를 찾아나가는 방법
- Cost function 의 Gradient에 상수를 곱한 값을 빼서 θ 를 조정
-
더보기→ Cost function에서 경사가 아래로 되어있는 방향으로 내려가서 Cost가 최소가 되는 지점을 찾는다. 어느 방향으로 θ를 움직이면 Cost 값이 작아지는지 현재 θ 위치에서 Cost 함수를 미분하여 판단
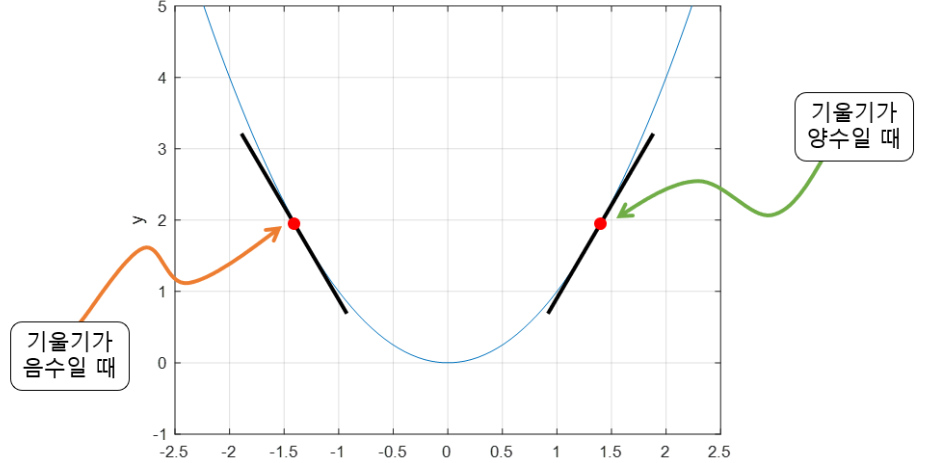
미분했을 때 기울기가 음수이면 양수 방향으로 이동, 기울기가 양수면 음수 방향으로 이동시킨다.
- Error가 제일 낮은 지점 : Global Minimum (전역 최솟값)
- 변수 (θ)의 초기값을 설정
- 현재 변수 값에 대응되는 Cost function이 경사도 계산(미분)
- 변수를 경사 방향(기울기의 음의 방향 = Gradient의 음의 방향)으로 움직여 다음 변수 값으로 설정
- 1 ~ 3을 반복하며 Cost function이 최소가 되도록 하는 변수 값으로 근접해 나간다. (= 전체 Cost 값이 변하지 않거나 매우 느리게 변할 때까지 접근)
- Gradient : 모든 변수의 편미분을 벡터로 정리한 것(= 함수의 기울기, 경사)
- 편미분 : 변수가 2개 이상인 함수를 미분할 때 미분 대상 변수 외에 나머지 변수를 상수처럼 고정시켜 미분하는 것
Learning Rate (학습률 = 보폭 step size) : 얼마나 큰 보폭으로 움직일지를 결정해주는 값
- 보통 0.01 or 0.001을 사용
- 물론 모델에 따라 적합한 학습률은 다르다.
- Hyper-parameter(초매개변수) : 사람이 정해주는 값
Auto ML = Auto F.E(데이터 전처리) + Auto M.S(모델 선택) + Auto HPO(하이퍼파라미터 최적화)
HPO(Hyper Parameter Tuning) = Model Tuning
Parameter θ(컴퓨터가 자동으로 찾아줌) vs Hyper Parameter(사람이 정함)
- 실제 Gradient Descent를 적용할 때에는 모든 θ에 대해 동시에 적용한다. (동시에 고려된다.)
- MSE' = 0 이라고 미분 방정식을 세우면 다 해결되지 않나? → 맞는 말이다. Gradient Descent도, 미분방정식을 0으로 세팅하는 것도 optimization의 한 일종이라고 보면 된다. 방법이 여러갈래로 나뉘는 것 뿐이지 옳고 그름의 문제는 아니다. 다만, 우리가 Gradient Descent를 자주 쓰는 이유는 딥러닝을 할 때 문제가 생기기 때문이다. 딥러닝에서 데이터가 많음에 따라 연산량이 어마어마하게 많아지기 때문에(역행렬을 구해야 함) 미분방정식을 0으로 세우고 최적의 값을 찾는 방법은 거의 불가능에 가깝다고 생각하면 된다. 따라서 Gradient Descent를 자주 쓴다.
- 전통적인 머신러닝, 즉 예를 들어 선형회귀 같은 경우에는 미분방적식 = 0으로 세우고 최적의 값을 찾는 것이 시간이 짧게 걸리기 때문에 선형회귀 때는 Gradient Descent를 쓰지 않고, 미분 방정식을 0으로 세팅하고 값을 찾는다.
- θ 에 따른 MSE 값을 함수로 그렸을 때 울퉁불퉁하게 그려진다면? → local minima / 전역 최솟값이 아닌 local minima가 여러 개일 수도 있다. 즉, 함정에 빠질 수도 있는데 이미 관성을 이용해서 local minima를 빠져나올 수 있는 방법이 많이 연구되었다. 물론 그러한 방법을 적용 시키더라도 local minima에 빠질 수 있지만, 딥러닝 전문가들이 주장하는 바로는, 그렇게 local minima에 빠지더라도 거의 Global Minimum에 근접한 값일 것이므로 모델 성능에서는 큰 차이가 없을 것이라고 말한다.
'AI > AI' 카테고리의 다른 글
| 로지스틱 회귀 (sigmoid function & Cutoff, Cross-entropy & Softmax, Accuracy & Recall & Precision, ROC Curve & AUC) (0) | 2024.07.09 |
|---|---|
| 선형 회귀 실습(Scikit-learn & One-hot encoding) (0) | 2024.07.08 |
| 머신러닝 기초 (capacity, overfitting, K-Fold cross validation) (0) | 2024.07.08 |
| 그로스 해킹을 위한 파이썬 통계 분석 (0) | 2024.07.04 |
| 교차 검정 (p-value) (0) | 2024.07.04 |

